
AWS Certified Data Engineer Associate認定試験でRedshiftに関するハンズオンをしたかったので、Redshift Serverlessを構築してみる。
1. Redshift Serverlessとは
従来のRedshiftを構築する際は、クラスタを構成するノード数やインスタンスタイプの設定、コンピューティングノードのスライス設定など手間がかかるかつインスタンスタイプによっては高額になってしまうところをRedshift Serverlessであればサーバレスの特性を活かし、ノード部分の設定側を意識せず低コストで構築できる機能になります。
クラスタの概念がなくなり、「名前空間」「ワークグループ」というコンポーネントによってRedshiftを管理します。
名前空間やワークグループなどRedshift Serverlessに関する記事は以下が参考になります。

2. 前提
- 新規AWSアカウントを作成し、無料利用枠で実施
- Organizationから検証用アカウントを作成することをお勧めします
3. Redshift Serverlessを構築してみる
以下AWS公式チュートリアルをもとに一通りRedshift Serverlessを組んでみる


- AWSマネジメントコンソールから[Redshift]を開く
- Redshiftトップ画面の[Redshift Serverlessの無料トライアルをお試しください]を選択
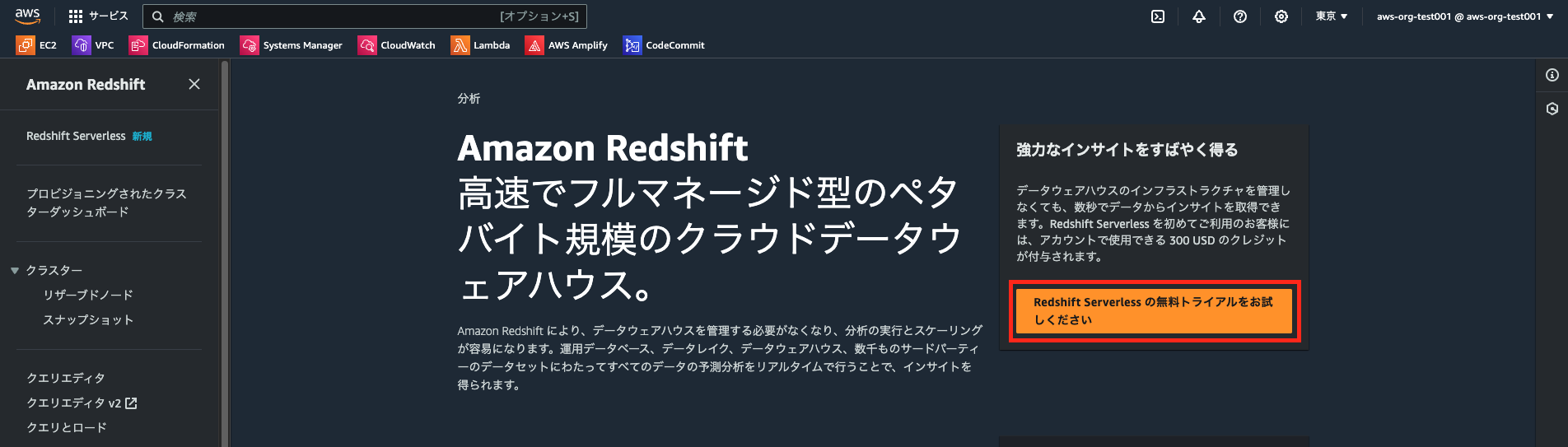
- [設定]セクションは[デフォルト設定を使用]を選択
[デフォルト設定を使用]を洗濯していると[名前空間]セクション内の設定は自動設定された状態になる。[設定をカスタマイズ]を設定していると[名前空間]セクションのカスタマイズが可能。
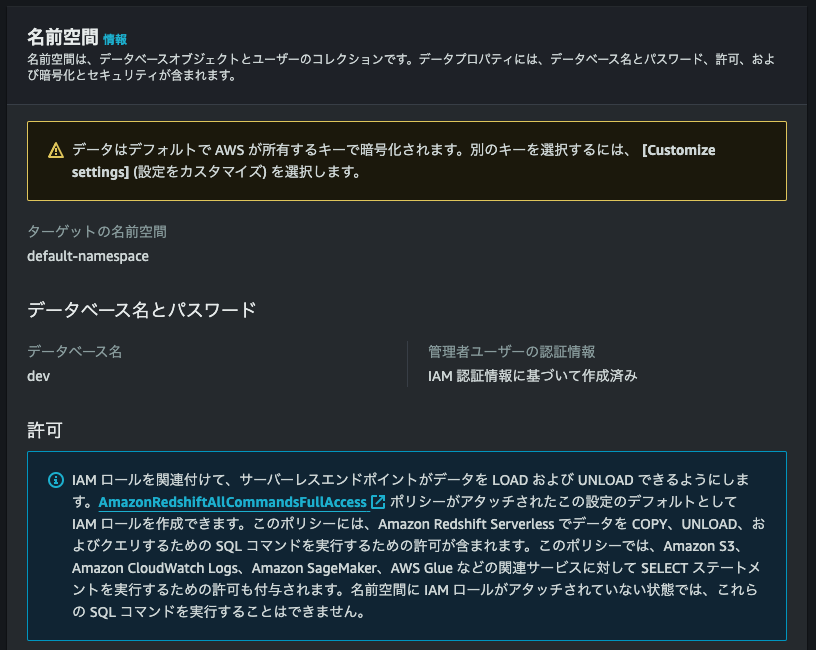
- その他の設定は行わず、[設定を保存]する
すると、以下のような画面が表示されるので、Redshift Serverlessが作成されるまで待機(数分ほど)
Redshift Serverlessの作成が完了したら、以下のように[complete]が表示されるので、[次へ]を選択
- Redshift Serverless ダッシュボードを確認する
サーバレスダッシュボード画面の[名前空間/ワークグループ]に作成した名前空間が利用可能状態になっていることを確認
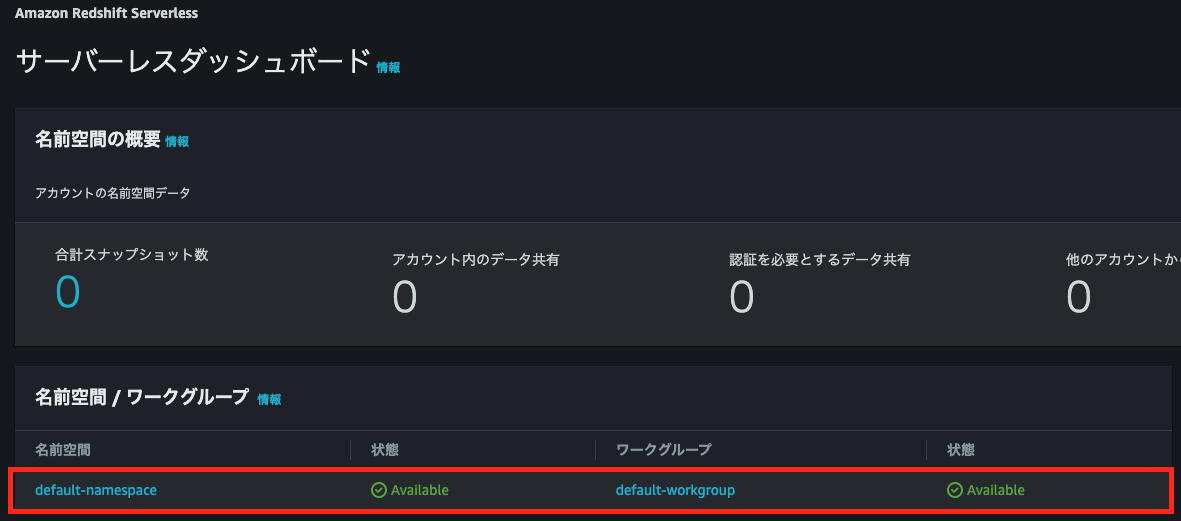
- サンプルデータをロードする
Redshift Serverlessが作成できているので、サーバレスダッシュボード画面の[データをクエリ]からデータをクエリすることができるので選択する
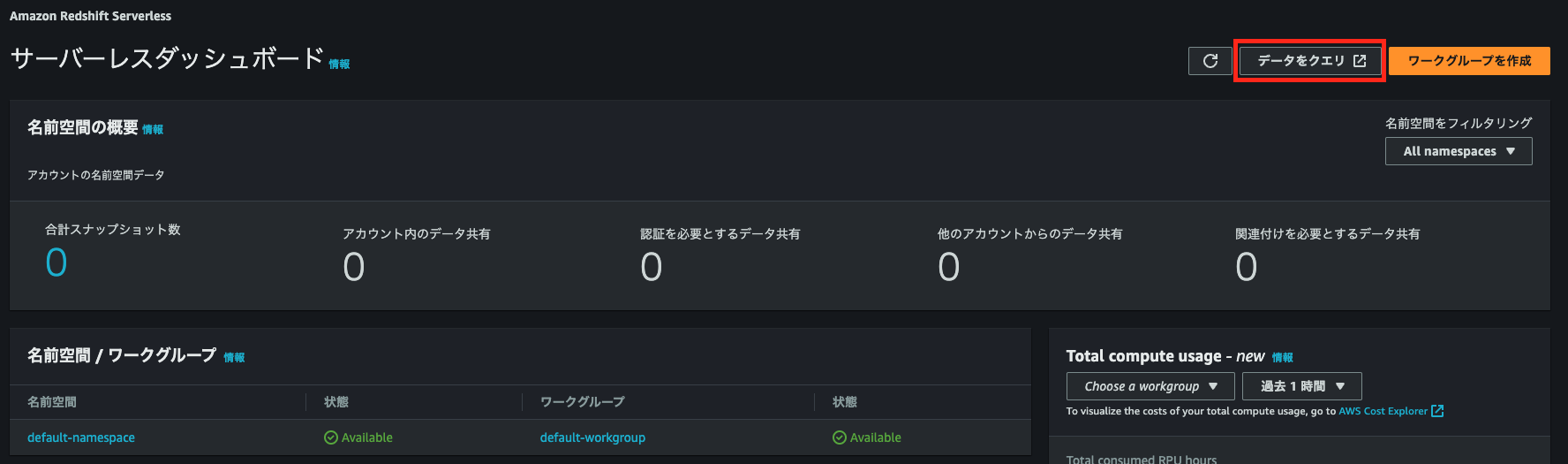
すると、Redshift query editor v2画面が表示される
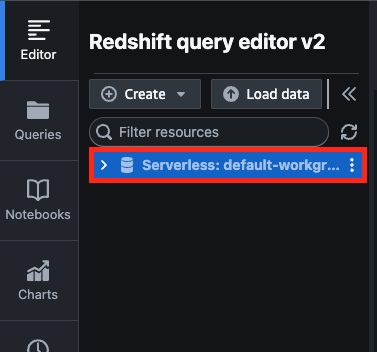
Redshift query editor v2画面のリソース一覧にさきほど作成したServerlessが表示されているので選択する
すると、ワークグループに接続するための設定画面が表示される。今回はハンズオン通りに進めるのでデフォルト設定のまま[Create connection]を選択する。実務では要件によって接続情報の設定が必要になる。
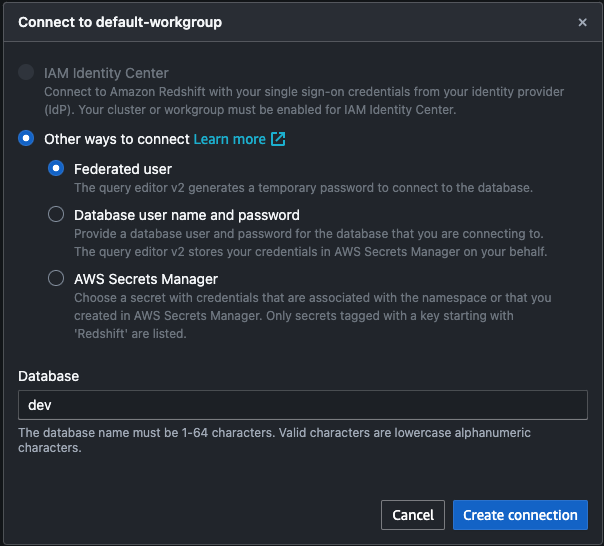
正常に接続ができた場合、Serverlessリソース配下に3つのスキ-マが作成される。これらのスキーマにあるデータセットをRedshift Serverless内にロードすることができる。
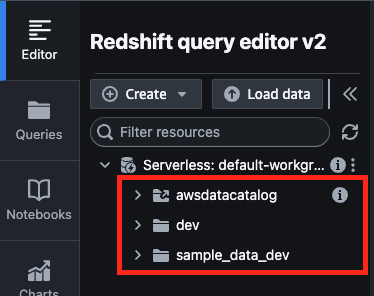
今回はハンズオン通りに進めるので、[sample_data_dev]>[tickit]データセットを選択し、Redshift Serverlessにロードする
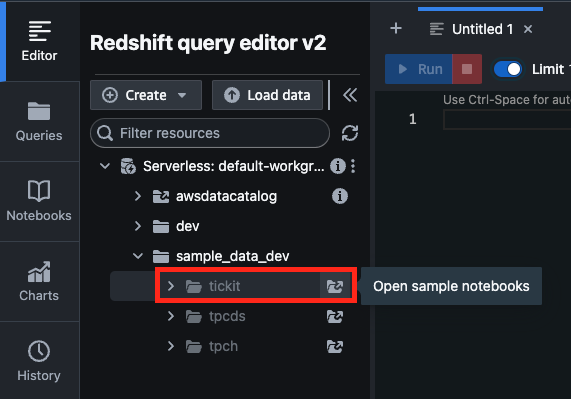
すると、初めてロードする際は以下のようなデータベース作成の確認画面が表示されるので、[Create]を選択する
正常にデータベースが作成されたら、以下のようにクエリエディタが表示される
- サンプルデータをクエリしてみる
クエリエディタ上部の[Run all]を選択し、サンプルクエリエディタの内容でクエリを実行してみる
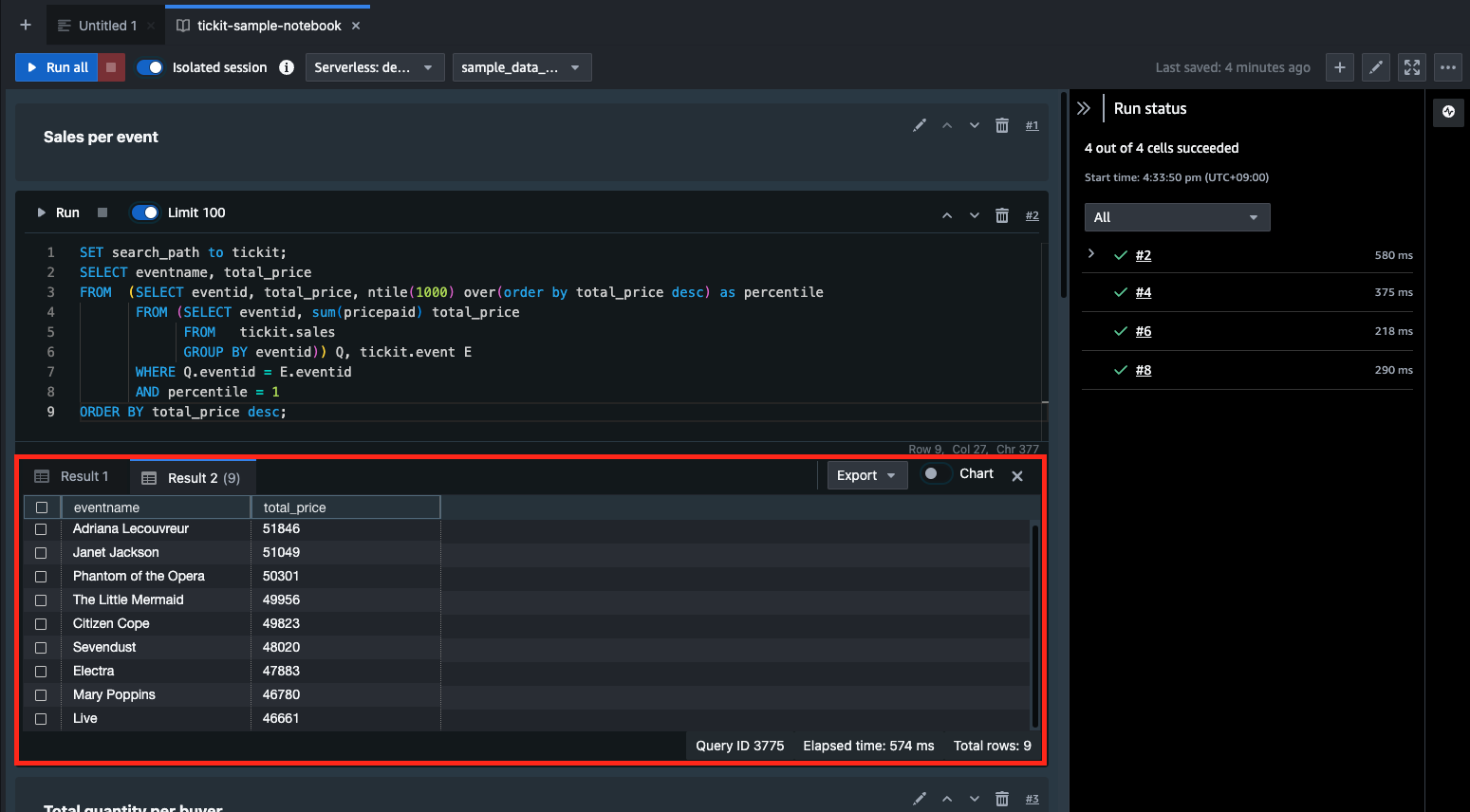
クエリが正常実行された場合、クエリ結果が各クエリエディタごとに出力される。[Result1]タブおよび[Result2]タブから詳細を確認することができる。
出力結果はJSONとCSVでDLできる
[Chart]を有効にすることで、グラフを表示することができる
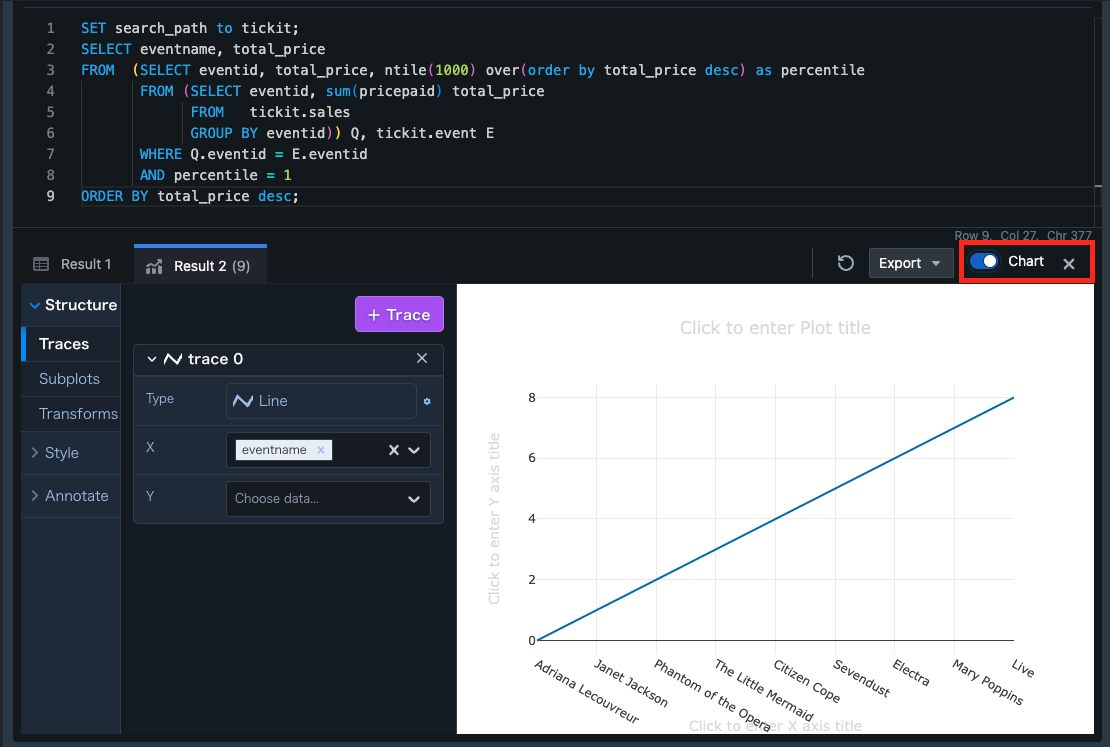
グラフの場合、PNGとJPEGでDLできる
4. Redshift ServerlessにS3データをロードしてみる
Redshift Serverlessの基本的な構築はできたので、実務でもありそうなReshift ServerlessにS3上のデータをロードしてみる
- 名前空間の設定を行う
S3からデータをロードする前に、IAMロールを作成して名前空間にアタッチする必要がある。[Redshift]>[名前空間の設定]から対象名前空間の詳細画面を開く

名前空間詳細画面の[セキュリティと暗号化]タブから[IAMロールを管理]を選択
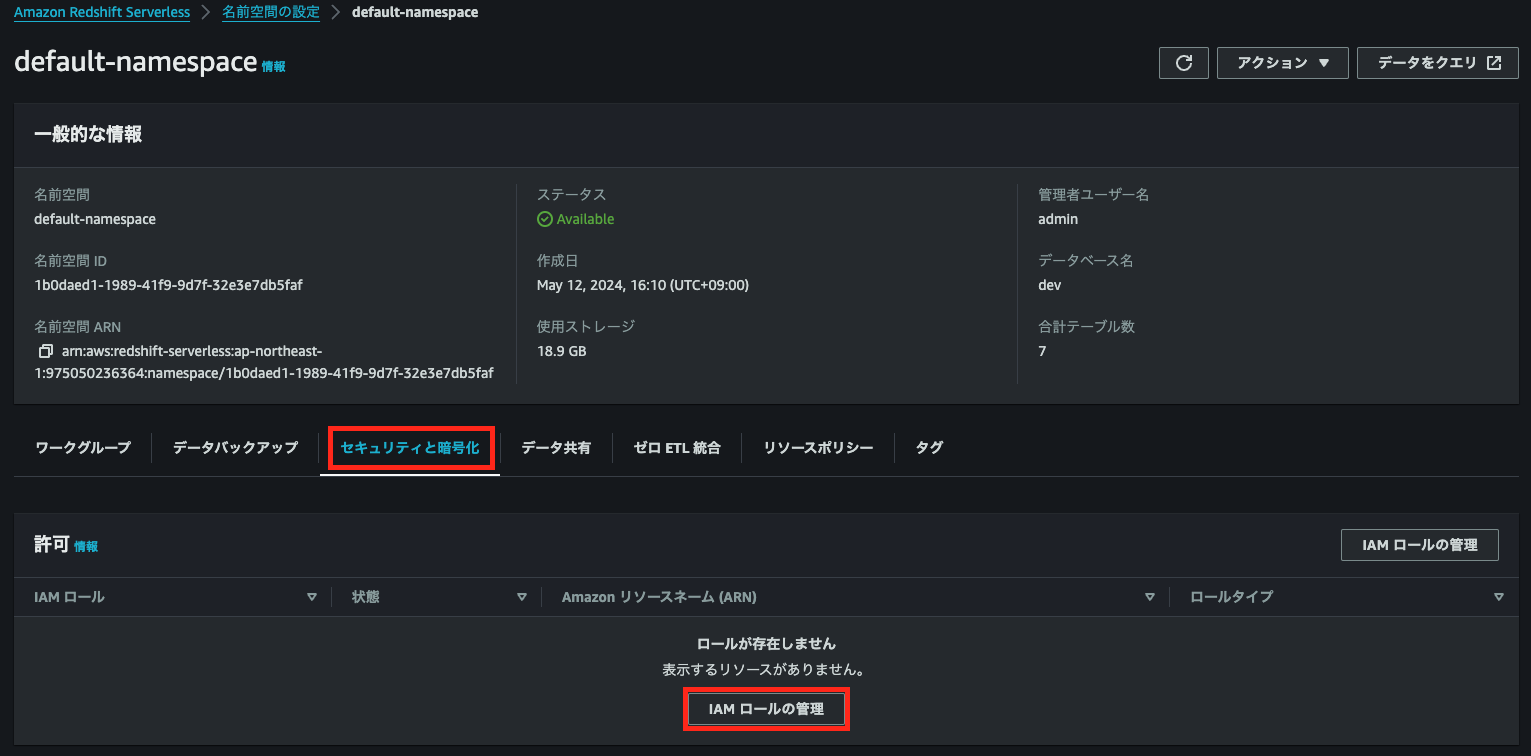
すると、IAMロールの設定画面が表示される。[IAMロールの管理]>[IAMロールを作成]を選択する。
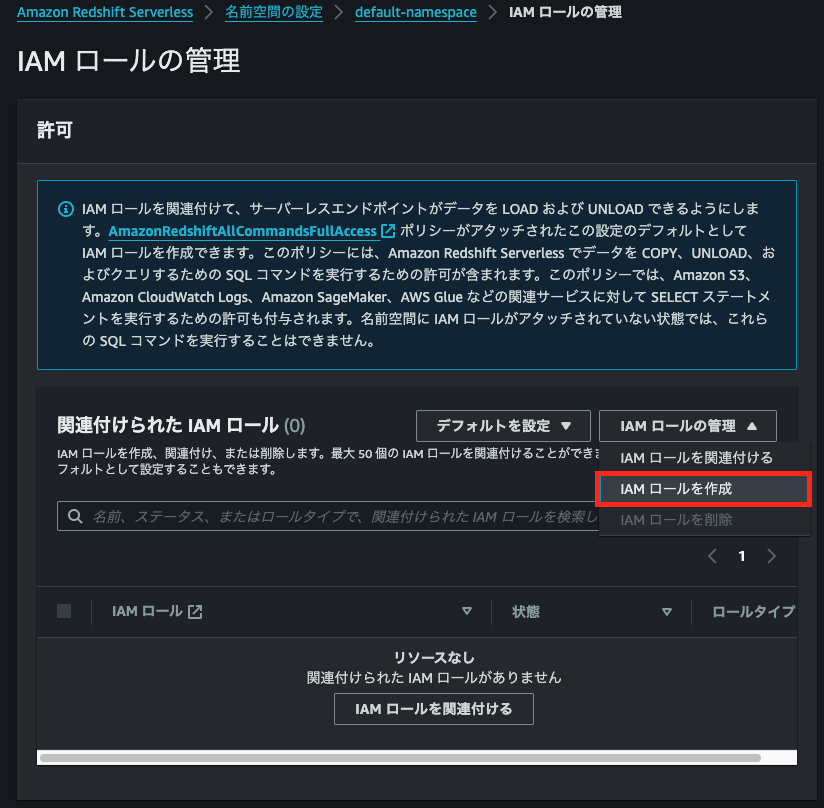
今回はハンズオンなので、[任意のS3バケット]を選択し、[IAMロールをデフォルトとして作成する]を選択する。実務ではIAMの最小権限の原則に従い、必要な権限のみをアタッチするようにすること。
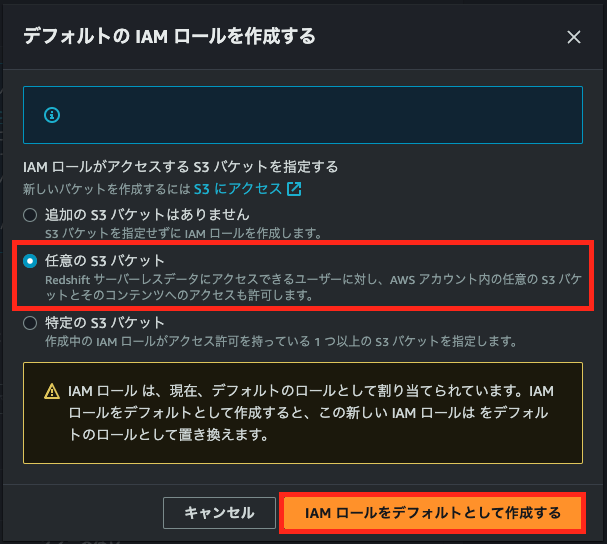
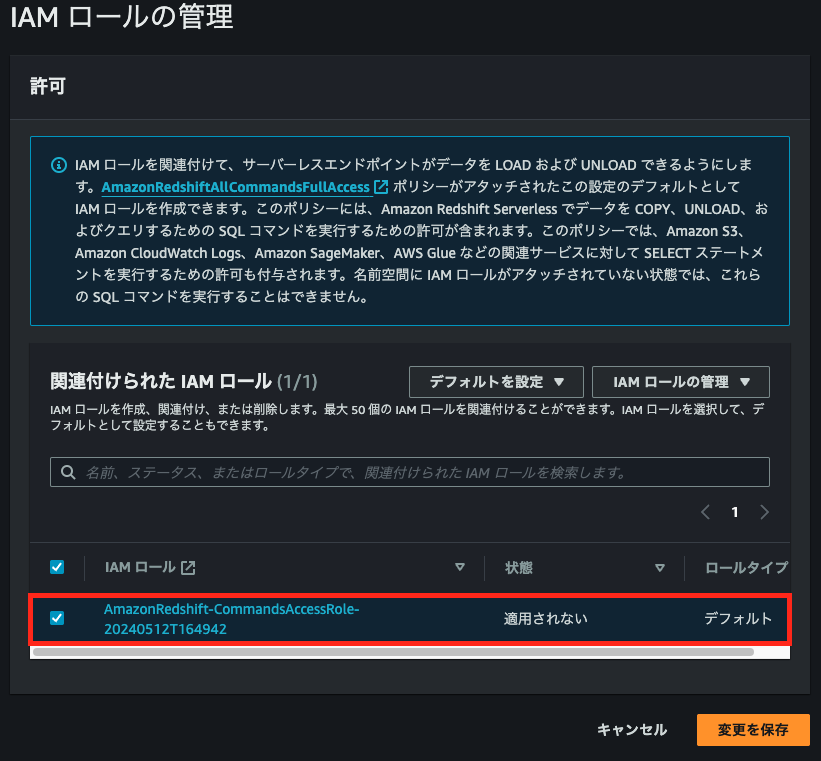
[関連付けられたIAMロール]の一覧にIAMロールが作成されていることを確認して、[変更を保存]を選択する
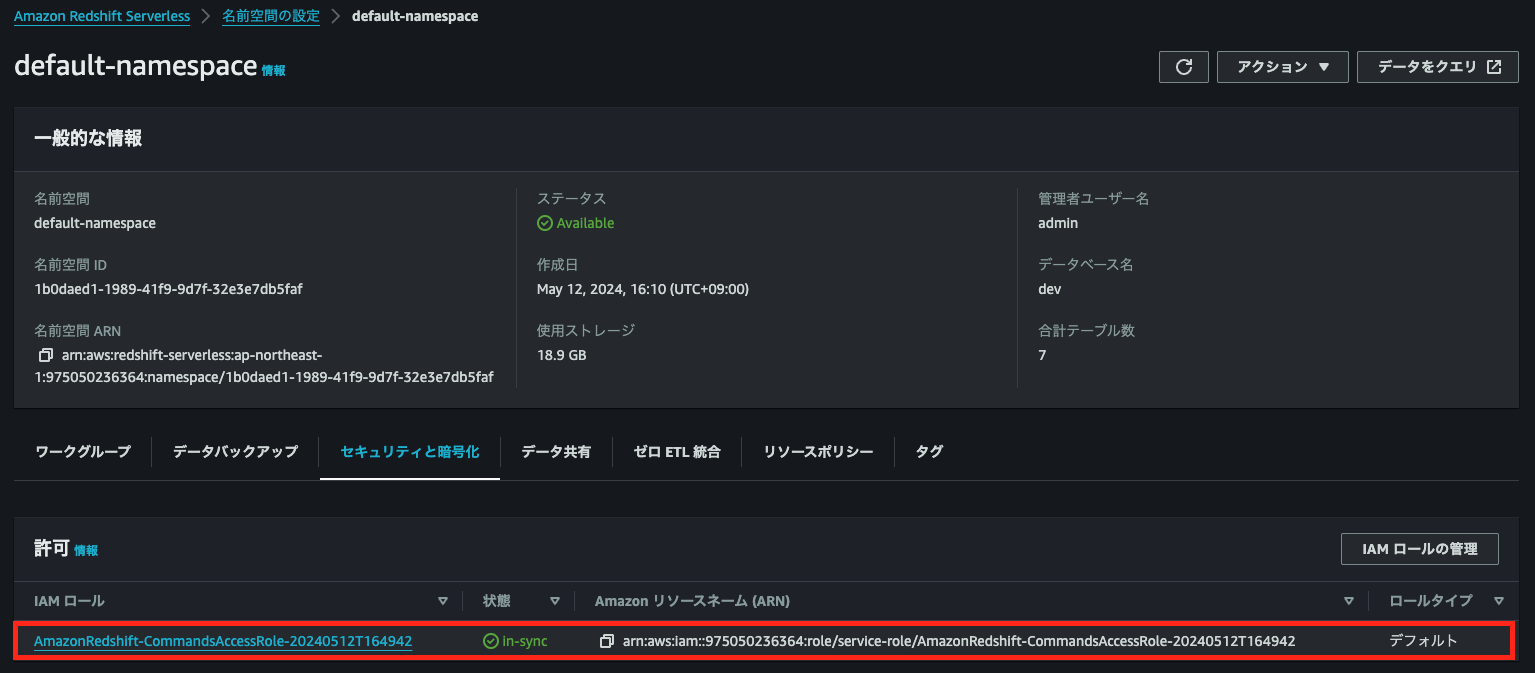
さきほど指定したIAMロールが名前空間と同期(in-sync)されたことを確認する
- S3からデータを実際にロードしてみる
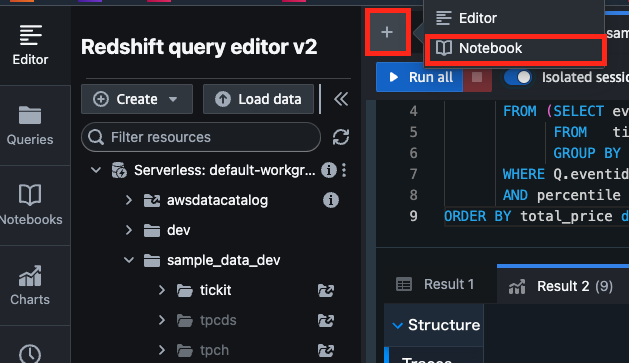
Redshift query editor v2画面に戻り、以下のように[+]>[Notebook]を選択する。Notebookを選択することで、新たにSQLノートブックを作成することができる。Notebookを使用することでインタラクティブにSQLクエリを実行することができる。

今回は、devデータベースを選択する
以下をクエリエディタにコピペする。以下はdevデータベースにテーブルを新規作成するクエリになる。
CREATE TABLEの詳細は以下AWS公式にあります
create table users( userid integer not null distkey sortkey, username char(8), firstname varchar(30), lastname varchar(30), city varchar(30), state char(2), email varchar(100), phone char(14), likesports boolean, liketheatre boolean, likeconcerts boolean, likejazz boolean, likeclassical boolean, likeopera boolean, likerock boolean, likevegas boolean, likebroadway boolean, likemusicals boolean); create table event( eventid integer not null distkey, venueid smallint not null, catid smallint not null, dateid smallint not null sortkey, eventname varchar(200), starttime timestamp); create table sales( salesid integer not null, listid integer not null distkey, sellerid integer not null, buyerid integer not null, eventid integer not null, dateid smallint not null sortkey, qtysold smallint not null, pricepaid decimal(8,2), commission decimal(8,2), saletime timestamp);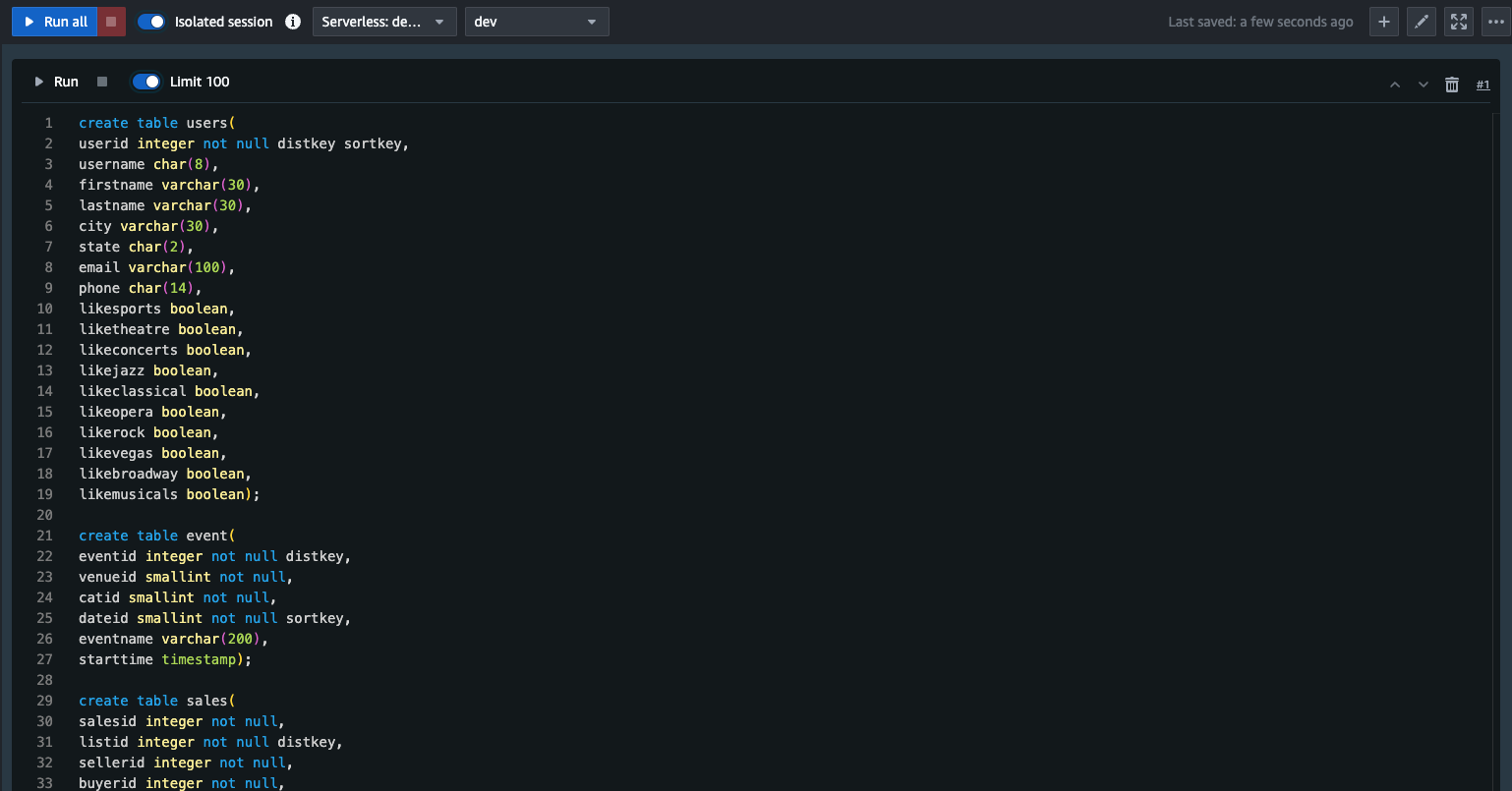
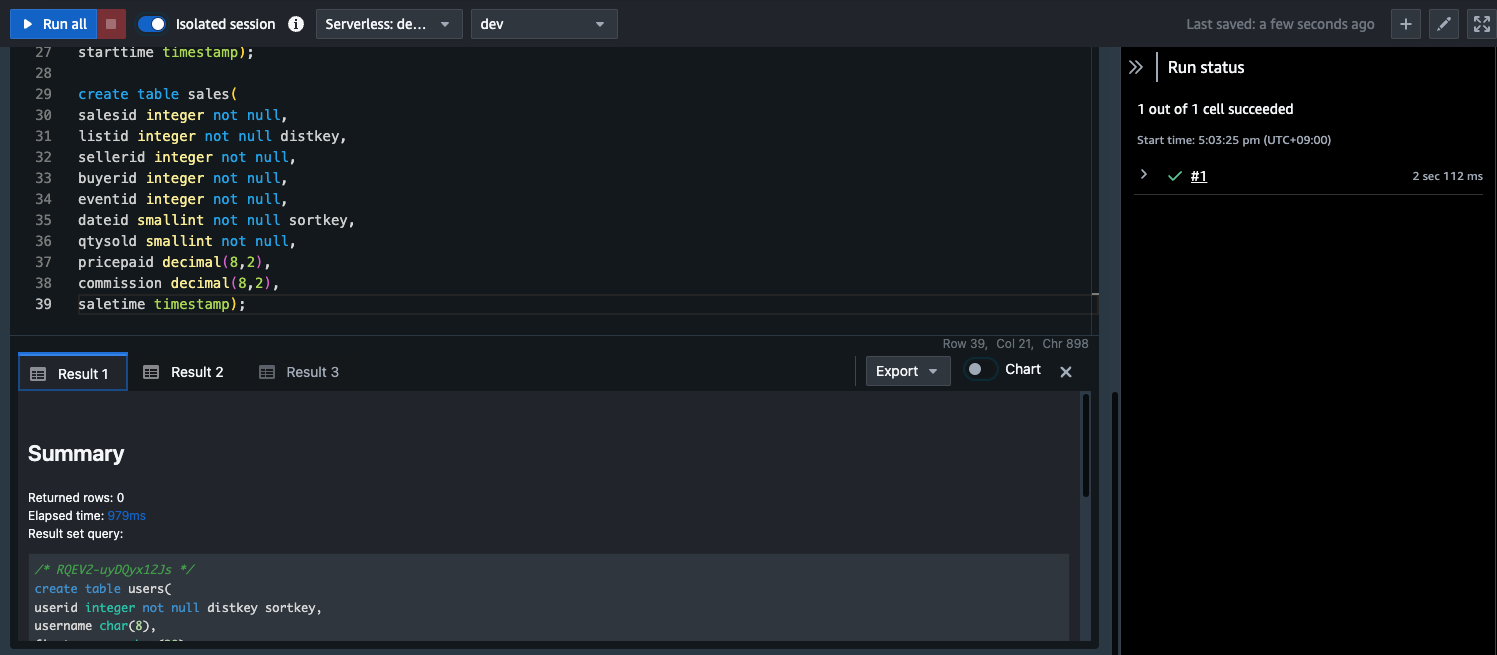
その後、[Run]を選択してクエリを実行する

クエリが正常実行されたこと[Result1][Result2][Result3]タブから確認する
S3からデータをロードするため、[+]>[SQL]を選択してSQLを入力するためのセルを新規追加する。

以下S3バケットからデータをロードするためのCOPYコマンドをセル内に設定する。
COPYコマンドの詳細は以下AWS公式にあります
COPY users FROM 's3://redshift-downloads/tickit/allusers_pipe.txt' DELIMITER '|' TIMEFORMAT 'YYYY-MM-DD HH:MI:SS' IGNOREHEADER 1 REGION 'us-east-1' IAM_ROLE 'arn:aws:iam::<aws-account-id>:role/<role-name>'; COPY event FROM 's3://redshift-downloads/tickit/allevents_pipe.txt' DELIMITER '|' TIMEFORMAT 'YYYY-MM-DD HH:MI:SS' IGNOREHEADER 1 REGION 'us-east-1' IAM_ROLE 'arn:aws:iam::<aws-account-id>:role/<role-name>'; COPY sales FROM 's3://redshift-downloads/tickit/sales_tab.txt' DELIMITER '\t' TIMEFORMAT 'MM/DD/YYYY HH:MI:SS' IGNOREHEADER 1 REGION 'us-east-1' IAM_ROLE 'arn:aws:iam::<aws-account-id>:role/<role-name>';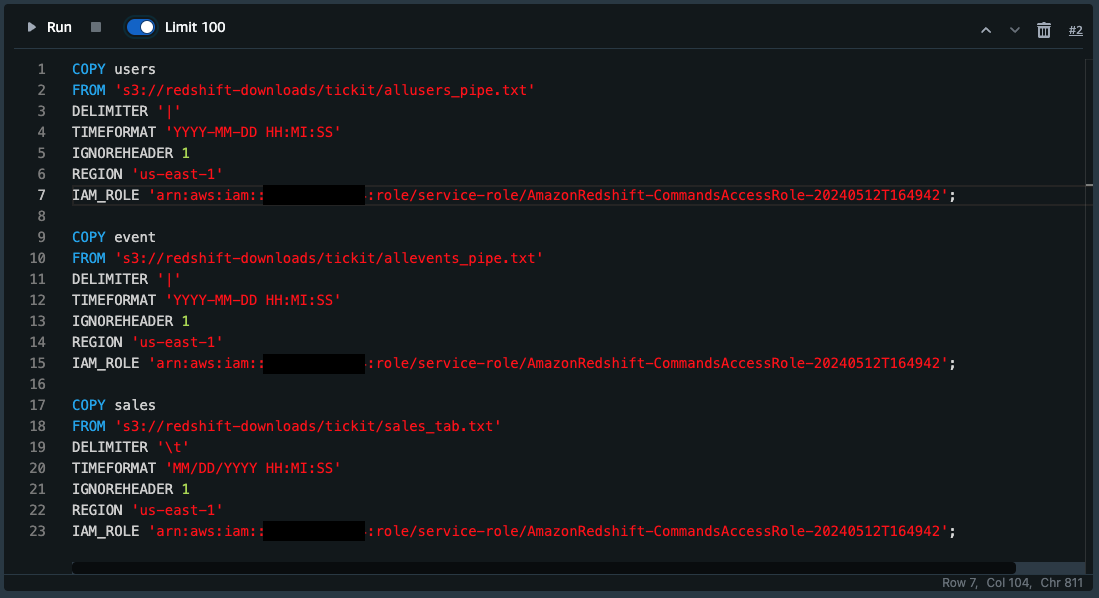
[Run]を選択して、S3からサンプルデータをロードする
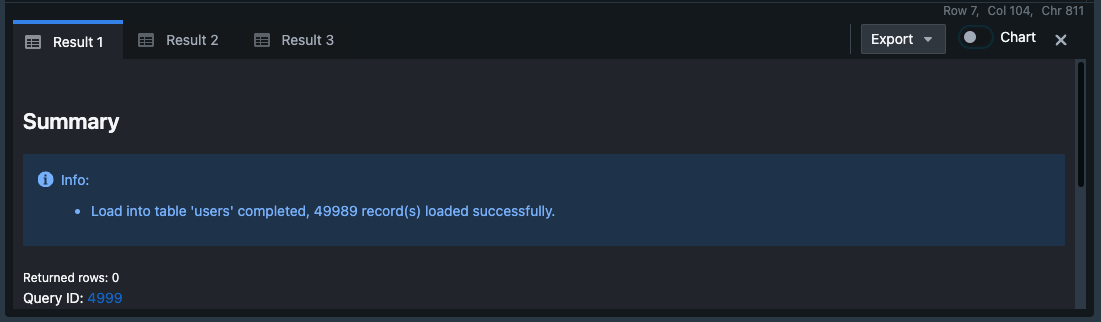
正常にロードか完了した場合、[Result1][Result2][Result3]タブにsuccessfullyの文字が表示されている
S3からロードしたデータをSELECTしてみる。新たにSQLセルを追加し、以下のクエリをコピペ実行する。
SELECT構文の詳細は以下AWS公式にあります
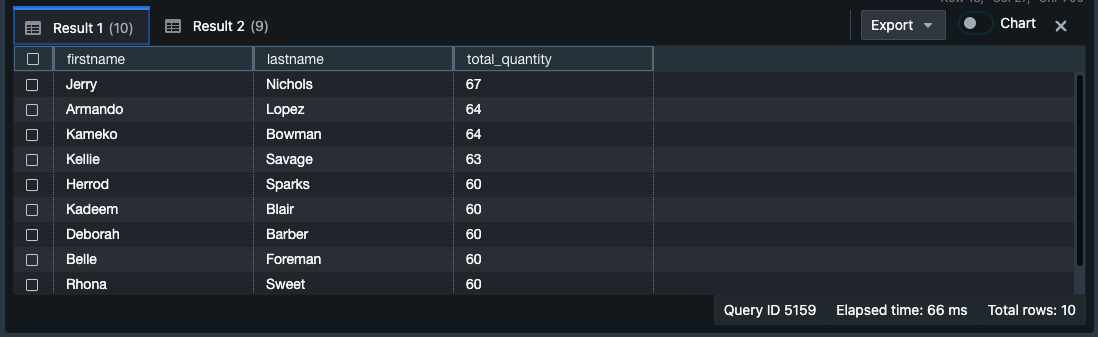
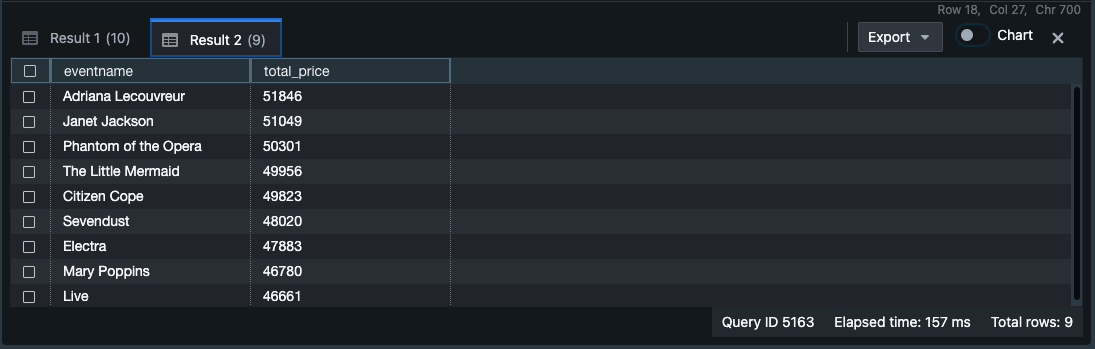
-- Find top 10 buyers by quantity. SELECT firstname, lastname, total_quantity FROM (SELECT buyerid, sum(qtysold) total_quantity FROM sales GROUP BY buyerid ORDER BY total_quantity desc limit 10) Q, users WHERE Q.buyerid = userid ORDER BY Q.total_quantity desc; -- Find events in the 99.9 percentile in terms of all time gross sales. SELECT eventname, total_price FROM (SELECT eventid, total_price, ntile(1000) over(order by total_price desc) as percentile FROM (SELECT eventid, sum(pricepaid) total_price FROM sales GROUP BY eventid)) Q, event E WHERE Q.eventid = E.eventid AND percentile = 1 ORDER BY total_price desc;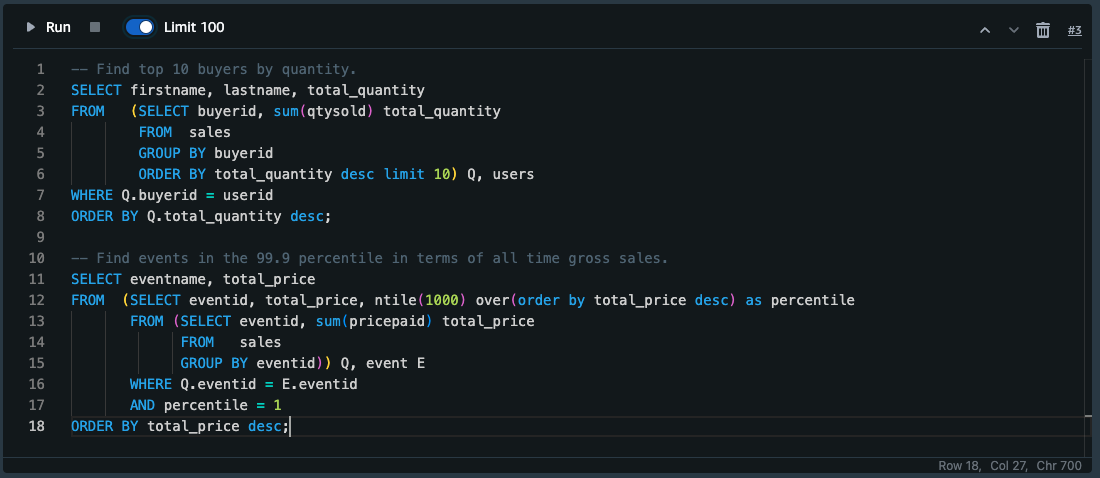
すると、S3からロードされたデータがクエリでき、出力結果に表示されるはず
5. リソースのクリーンアップ
Redshift Serverlessなので、Redshiftと違いクエリ実行による従量課金となるので、立ち上げた状態でも課金は発生しないが、念の為リソースはクリーンアップしておく
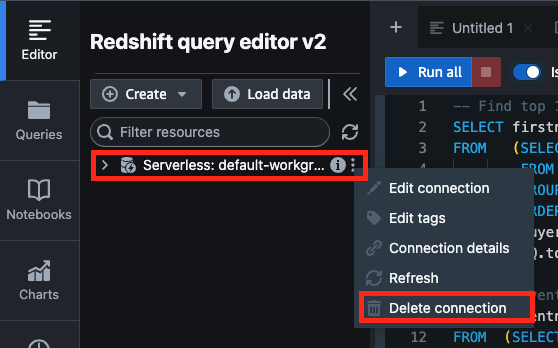
- Resshift query editor v2の接続を切断
Redshift query editor v2画面から対象のリソースの[Delete connection]を選択し、接続を切断する

- ワークグループの削除
[Redshift]>[ワークグループの設定]から対象ワークグループを選択し、[アクション]>[削除]を選択する

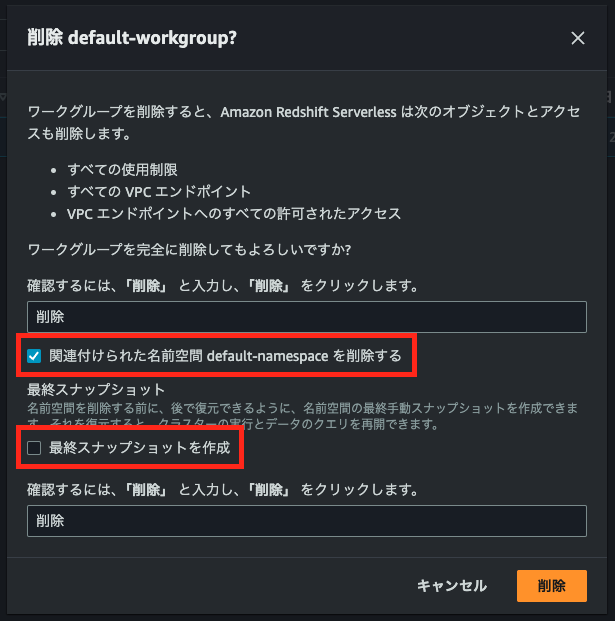
すると、ワークグループ削除の確認画面が表示される。ワークグループの削除に[削除]と入力する。
また、[関連付けられた名前空間***を削除する]にチェックを入れておくこと。
加えて、[最終スナップショットを作成]については今回ハンズオンなので、チェックを外すこと。実務の場合は、スナップショットを保持するかどうか確認が必要。スナップショットは保持している間料金が発生するので注意する。
内容に問題なければ[削除]を選択する
正常に削除されたら、サーバレスダッシュボードから[名前空間/ワークグループ]上にリソースがないことを確認すること
6. 感想・まとめ
ハンズオンに要した時間は30分ほどだった。Redshiftだとクラスタ作成からノード、スライスの設定など手動作成する部分が多く時間がかかるが、Redshift Serverlessの構築は短時間でかつシンプルなアーキテクチャを構築可能ですね!
今回のハンズオンではS3からサンプルデータをロードしてみたが、Redshift Spectrumなど直接データロードせずにS3上のデータをクエリする部分についても検証してみたい。